Dask Development Log
This work is supported by Anaconda Inc
To increase transparency I’m trying to blog more often about the current work going on around Dask and related projects. Nothing here is ready for production. This blogpost is written in haste, so refined polish should not be expected.
Over the last two weeks we’ve seen activity in the following areas:
- An experimental Actor solution for stateful processing
- Machine learning experiments with hyper-parameter selection and parameter servers.
- Development of more preprocessing transformers
- Statistical profiling of the distributed scheduler’s internal event loop thread and internal optimizations
- A new release of dask-yarn
- A new narrative on dask-stories about modelling mobile networks
- Support for LSF clusters in dask-jobqueue
- Test suite cleanup for intermittent failures
Stateful processing with Actors
Some advanced workloads want to directly manage and mutate state on workers. A task-based framework like Dask can be forced into this kind of workload using long-running-tasks, but it’s an uncomfortable experience. To address this we’ve been adding an experimental Actors framework to Dask alongside the standard task-scheduling system. This provides reduced latencies, removes scheduling overhead, and provides the ability to directly mutate state on a worker, but loses niceties like resilience and diagnostics.
The idea to adopt Actors was shamelessly stolen from the Ray Project :)
Work for Actors is happening in dask/distributed #2133.
class Counter:
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
return self.n
counter = client.submit(Counter, actor=True).result()
>>> future = counter.increment()
>>> future.result()
1
Machine learning experiments
Hyper parameter optimization on incrementally trained models
Many Scikit-Learn-style estimators feature a partial_fit method that enables
incremental training on batches of data. This is particularly well suited for
systems like Dask array or Dask dataframe, that are built from many batches of
Numpy arrays or Pandas dataframes. It’s a nice fit because all of the
computational algorithm work is already done in Scikit-Learn, Dask just has to
administratively move models around to data and call scikit-learn (or other
machine learning models that follow the fit/transform/predict/score API). This
approach provides a nice community interface between parallelism and machine
learning developers.
However, this training is inherently sequential because the model only trains on one batch of data at a time. We’re leaving a lot of processing power on the table.
To address this we can combine incremental training with hyper-parameter selection and train several models on the same data at the same time. This is often required anyway, and lets us be more efficient with our computation.
However there are many ways to do incremental training with hyper-parameter selection, and the right algorithm likely depends on the problem at hand. This is an active field of research and so it’s hard for a general project like Dask to pick and implement a single method that works well for everyone. There is probably a handful of methods that will be necessary with various options on them.
To help experimentation here we’ve been experimenting with some lower-level tooling that we think will be helpful in a variety of cases. This accepts a policy from the user as a Python function that gets scores from recent evaluations, and asks for how much further to progress on each set of hyper-parameters before checking in again. This allows us to model a few common situations like random search with early stopping conditions, successive halving, and variations of those easily without having to write any Dask code:
This work is done by Scott Sievert and myself

Parameter Servers
To improve the speed of training large models Scott Sievert has been using Actors (mentioned above) to develop simple examples for parameter servers. These are helping to identify and motivate performance and diagnostic improvements improvements within Dask itself:
These parameter servers manage the communication of models produced by different workers, and leave the computation to the underlying deep learning library. This is ongoing work.
Dataframe Preprocessing Transformers
We’ve started to orient some of the Dask-ML work around case studies. Our first, written by Scott Sievert, uses the Criteo dataset for ads. It’s a good example of a combined dense/sparse dataset that can be somewhat large (around 1TB). The first challenge we’re running into is preprocessing. These have lead to a few preprocessing improvements:
- Label Encoder supports Pandas Categorical dask/dask-ml #310
- Add Imputer with mean and median strategies dask/dask-ml #11
- Ad OneHotEncoder dask/dask-ml #313
- Add Hashing Vectorizer dask/dask-ml #122
- Add ColumnTransformer dask/dask-ml #315
Some of these are also based off of improved dataframe handling features in the upcoming 0.20 release for Scikit-Learn.
This work is done by Roman Yurchak, James Bourbeau, Daniel Severo, and Tom Augspurger.
Profiling the main thread
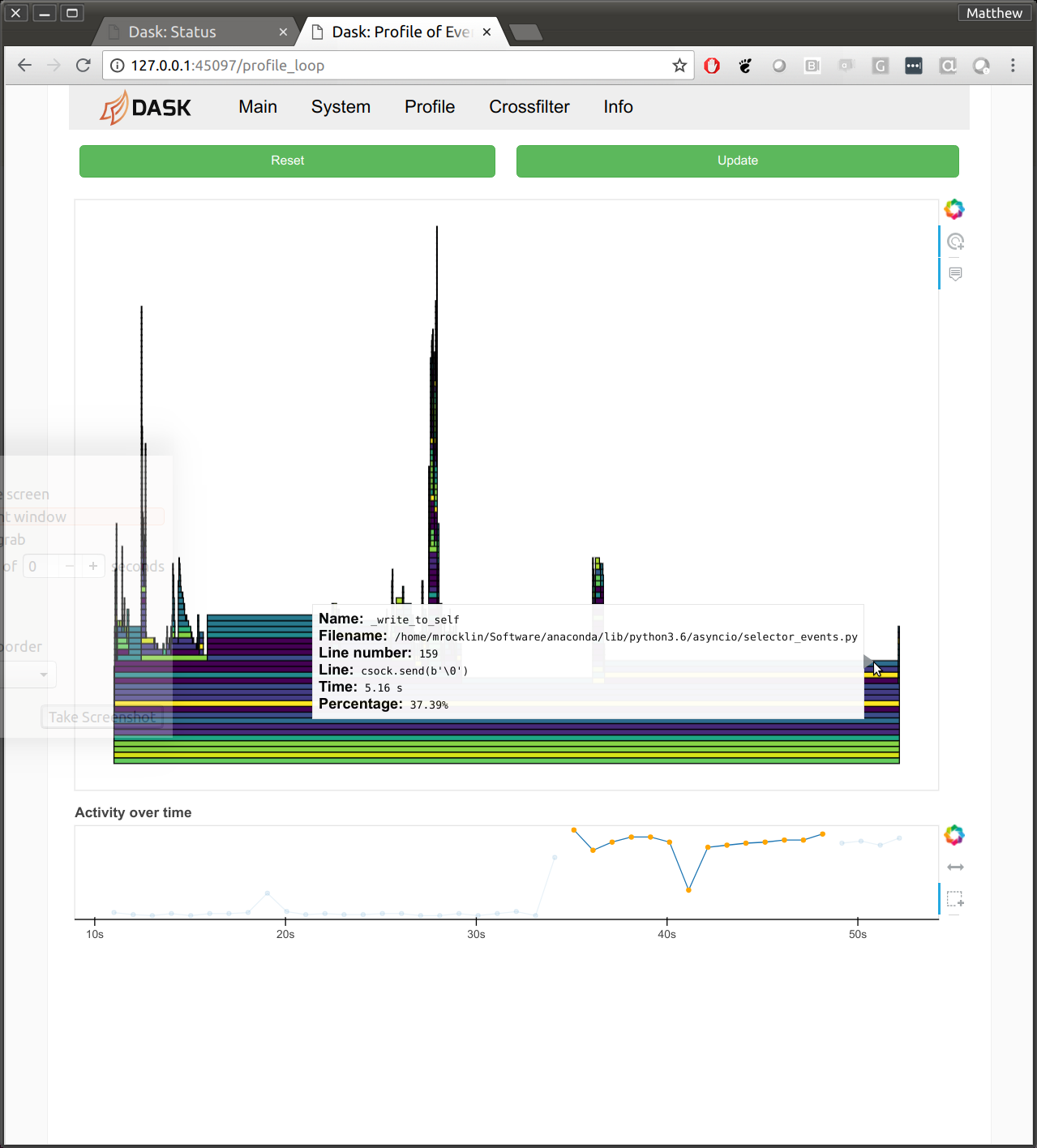
Profiling concurrent code is hard. Traditional profilers like CProfile become confused by passing control between all of the different coroutines. This means that we haven’t done a very comprehensive job of profiling and tuning the distributed scheduler and workers. Statistical profilers on the other hand tend to do a bit better. We’ve taken the statistical profiler that we usually use on Dask worker threads (available in the dashboard on the “Profile” tab) and have applied it to the central administrative threads running the Tornado event loop as well. This has highlighted a few issues that we weren’t able to spot before, and should hopefully result in reduced overhead in future releases.
- dask/distributed #2144
- stackoverflow.com/questions/51582394/which-functions-are-free-when-profiling-tornado-asyncio
New release of Dask-Yarn
There is a new release of Dask-Yarn and the underlying library for managing Yarn jobs, Skein. These include a number of bug-fixes and improved concurrency primitives for YARN applications. The new features are documented here, and were implemented in jcrist/skein #40.
This work was done by Jim Crist
Support for LSF clusters in Dask-Jobqueue
Dask-jobqueue supports Dask use on traditional HPC cluster managers like SGE, SLURM, PBS, and others. We’ve recently added support for LSF clusters
Work was done in dask/dask-jobqueue #78 by Ray Bell.
New Dask Story on mobile networks
The Dask Stories repository holds narrative about how people use Dask. Sameer Lalwani recently added a story about using Dask to model mobile communication networks. It’s worth a read.
Test suite cleanup
The dask.distributed test suite has been suffering from intermittent failures recently. These are tests that fail very infrequently, and so are hard to catch when writing them, but show up when future unrelated PRs run the test suite on continuous integration and get failures. They add friction to the development process, but are expensive to track down (testing distributed systems is hard).
We’re taking a bit of time this week to track these down. Progress here:
blog comments powered by Disqus