Dask Release 0.18.0
This work is supported by Anaconda Inc.
I’m pleased to announce the release of Dask version 0.18.0. This is a major release with breaking changes and new features. The last release was 0.17.5 on May 4th. This blogpost outlines notable changes since the last release blogpost for 0.17.2 on March 21st.
You can conda install Dask:
conda install dask
or pip install from PyPI:
pip install dask[complete] --upgrade
Full changelogs are available here:
We list some breaking changes below, followed up by changes that are less important, but still fun.
Context
The Dask core library is nearing a 1.0 release. Before that happens, we need to do some housecleaning. This release starts that process, replaces some existing interfaces, and builds up some needed infrastructure. Almost all of the changes in this release include clean deprecation warnings, but future releases will remove the old functionality, so now would be a good time to check in.
As happens with any release that starts breaking things, many other smaller breaks get added on as well. I’m personally very happy with this release because many aspects of using Dask now feel a lot cleaner, however heavy users of Dask will likely experience mild friction. Hopefully this post helps explain some of the larger changes.
Notable Breaking changes
Centralized configuration
Taking full advantage of Dask sometimes requires user configuration, especially in a distributed setting. This might be to control logging verbosity, specify cluster configuration, provide credentials for security, or any of several other options that arise in production.
We’ve found that different computing cultures like to specify configuration in several different ways:
- Configuration files
- Environment variables
- Directly within Python code
Previously this was handled with a variety of different solutions among the different dask subprojects. The dask-distributed project had one system, dask-kubernetes had another, and so on.
Now we centralize configuration in the dask.config module, which collects
configuration from config files, environment variables, and runtime code, and
makes it centrally available to all Dask subprojects. A number of Dask
subprojects (dask.distributed,
dask-kubernetes, and
dask-jobqueue), are being
co-released at the same time to take advantage of this.
If you were actively using Dask.distributed’s configuration files some things have changed:
-
The configuration is now namespaced and more heavily nested. Here is an example from the dask.distributed default config file today:
distributed: version: 2 scheduler: allowed-failures: 3 # number of retries before a task is considered bad work-stealing: True # workers should steal tasks from each other worker-ttl: null # like '60s'. Workers must heartbeat faster than this worker: multiprocessing-method: forkserver use-file-locking: True -
The default configuration location has moved from
~/.dask/config.yamlto~/.config/dask/distributed.yaml, where it will live along side several other files likekubernetes.yaml,jobqueue.yaml, and so on.
However, your old configuration files will still be found and their values
will be used appropriately. We don’t make any attempt to migrate your old
config values to the new location though. You may want to delete the
auto-generated ~/.dask/config.yaml file at some point, if you felt like being
particularly clean.
You can learn more about Dask’s configuration in Dask’s configuration documentation
Replaced the common get= keyword with scheduler=
Dask can execute code with a variety of scheduler backends based on threads, processes, single-threaded execution, or distributed clusters.
Previously, users selected between these backends using the somewhat
generically named get= keyword:
x.compute(get=dask.threaded.get)
x.compute(get=dask.multiprocessing.get)
x.compute(get=dask.local.get_sync)
We’ve replaced this with a newer, and hopefully more clear, scheduler= keyword:
x.compute(scheduler='threads')
x.compute(scheduler='processes')
x.compute(scheduler='single-threaded')
The get= keyword has been deprecated and will raise a warning. It will be
removed entirely on the next major release.
For more information, see documentation on selecting different schedulers.
Replaced dask.set_options with dask.config.set
Related to the configuration changes, we now include runtime state in the
configuration. Previously people used to set runtime state with the
dask.set_options context manager. Now we recommend using dask.config.set:
with dask.set_options(scheduler='threads'): # Before
...
with dask.config.set(scheduler='threads'): # After
...
The dask.set_options function is now an alias to dask.config.set.
Removed the dask.array.learn subpackage
This was unadvertised and saw very little use. All functionality (and much more) is now available in Dask-ML.
Other
- We’ve removed the
token=keyword from map_blocks and moved the functionality to thename=keyword. - The
dask.distributed.worker_clientautomatically rejoins the threadpool when you close the context manager. - The Dask.distributed protocol now interprets msgpack arrays as tuples rather than lists.
Fun new features
Arrays
Generalized Universal Functions
Dask.array now supports Numpy-style
Generalized Universal Functions (gufuncs)
transparently.
This means that you can apply normal Numpy GUFuncs, like eig in the example
below, directly onto a Dask arrays:
import dask.array as da
import numpy as np
# Apply a Numpy GUFunc, eig, directly onto a Dask array
x = da.random.normal(size=(10, 10, 10), chunks=(2, 10, 10))
w, v = np.linalg._umath_linalg.eig(x, output_dtypes=(float, float))
# w and v are dask arrays with eig applied along the latter two axes
Numpy has gufuncs of many of its internal functions, but they haven’t yet decided to switch these out to the public API. Additionally we can define GUFuncs with other projects, like Numba:
import numba
@numba.vectorize([float64(float64, float64)])
def f(x, y):
return x + y
z = f(x, y) # if x and y are dask arrays, then z will be too
What I like about this is that Dask and Numba developers didn’t coordinate at all on this feature, it’s just that they both support the Numpy GUFunc protocol, so you get interactions like this for free.
For more information see Dask’s GUFunc documentation. This work was done by Markus Gonser (@magonser).
New “auto” value for rechunking
Dask arrays now accept a value, “auto”, wherever a chunk value would previously be accepted. This asks Dask to rechunk those dimensions to achieve a good default chunk size.
x = x.rechunk({
0: x.shape[0], # single chunk in this dimension
# 1: 100e6 / x.dtype.itemsize / x.shape[0], # before we had to calculate manually
1: 'auto' # Now we allow this dimension to respond to get ideal chunk size
})
# or
x = da.from_array(img, chunks='auto')
This also checks the array.chunk-size config value for optimal chunk sizes
>>> dask.config.get('array.chunk-size')
'128MiB'
To be clear, this doesn’t support “automatic chunking”, which is a very hard problem in general. Users still need to be aware of their computations and how they want to chunk, this just makes it marginally easier to make good decisions.
Algorithmic improvements
Dask.array gained a full einsum implementation thanks to Simon Perkins.
Also, Dask.array’s QR decompositions has become nicer in two ways:
- They support short-and-fat arrays
-
The tall-and-skinny variant now operates more robustly in less memory. Here is a friendly GIF of execution:
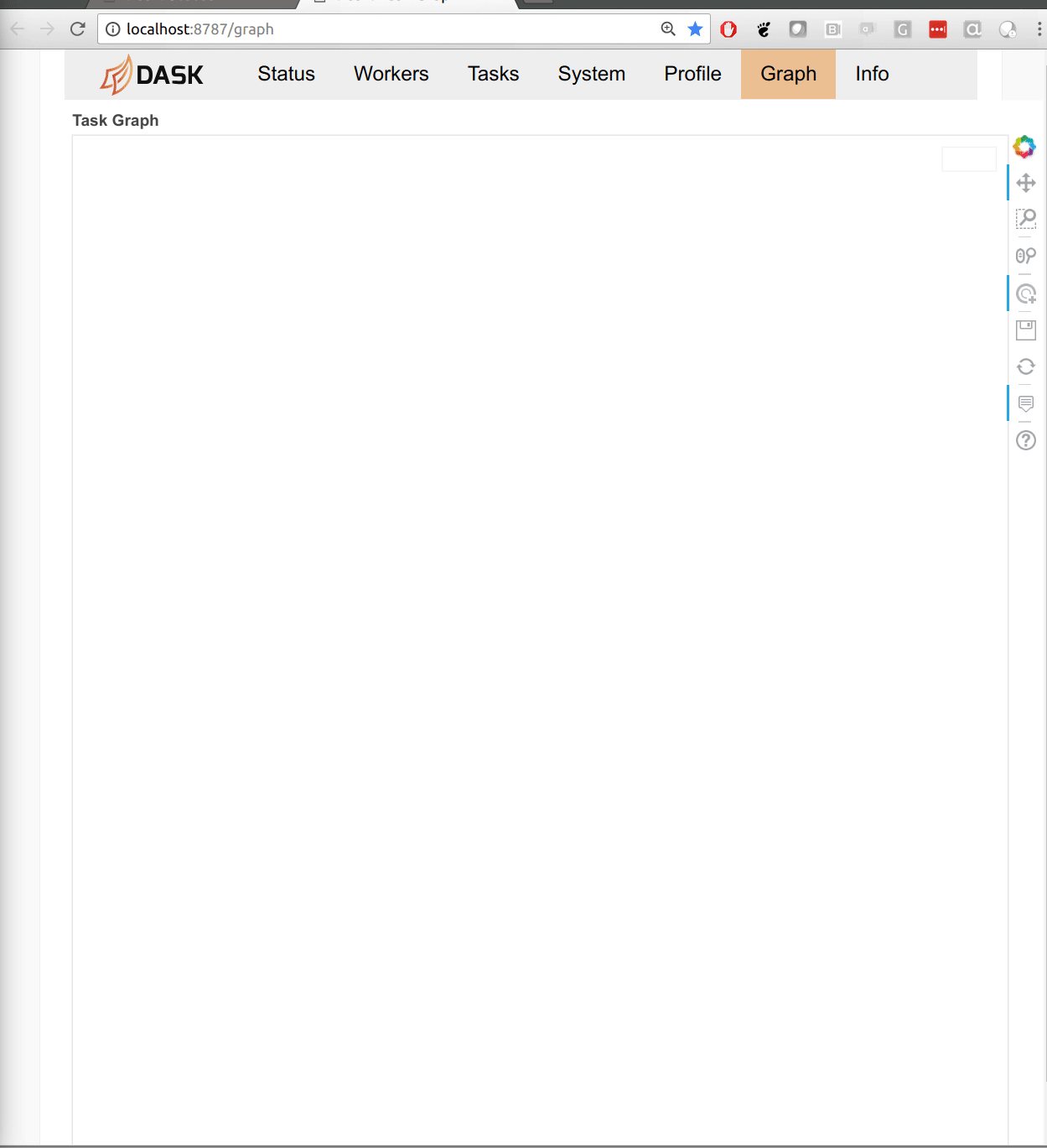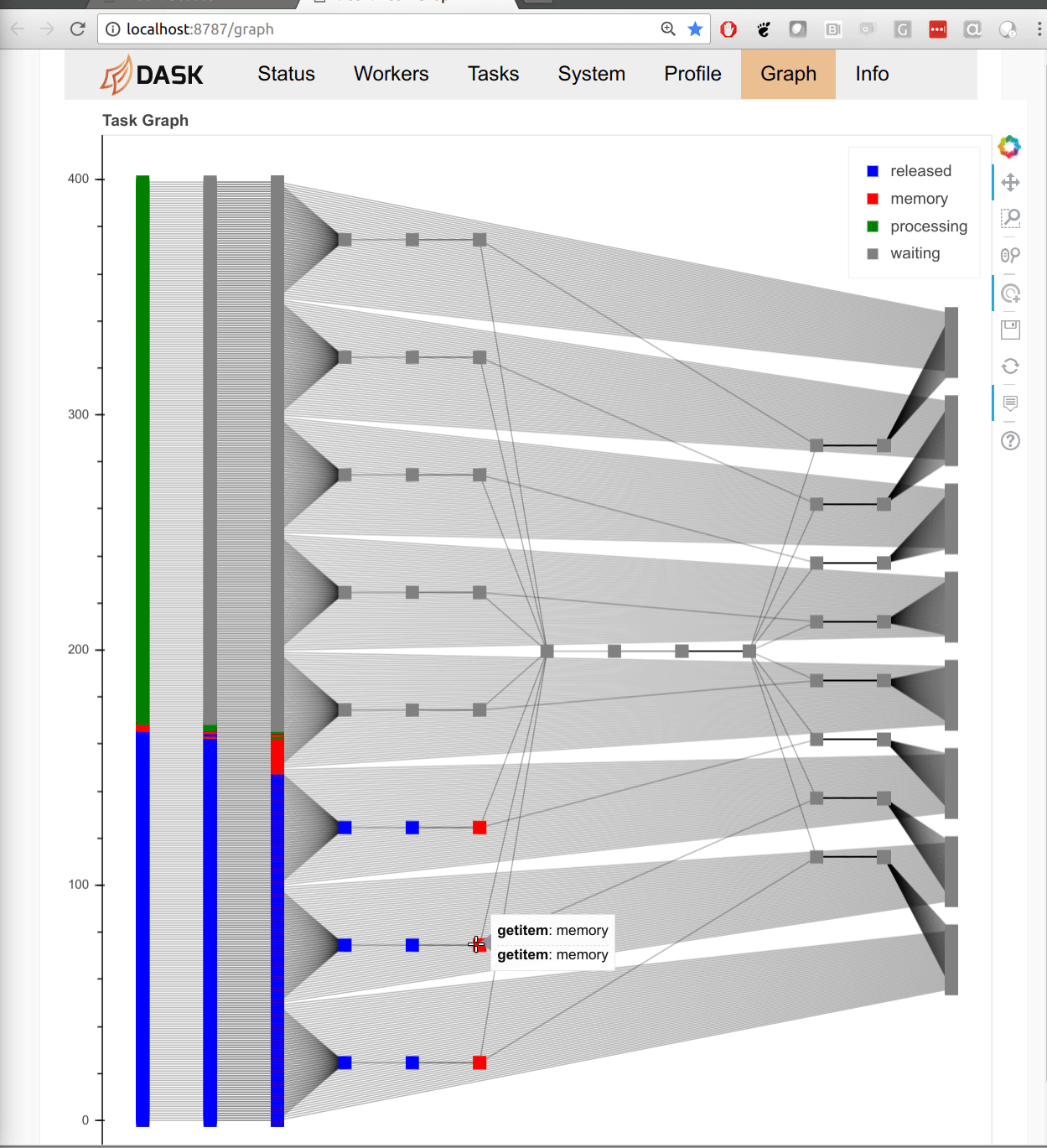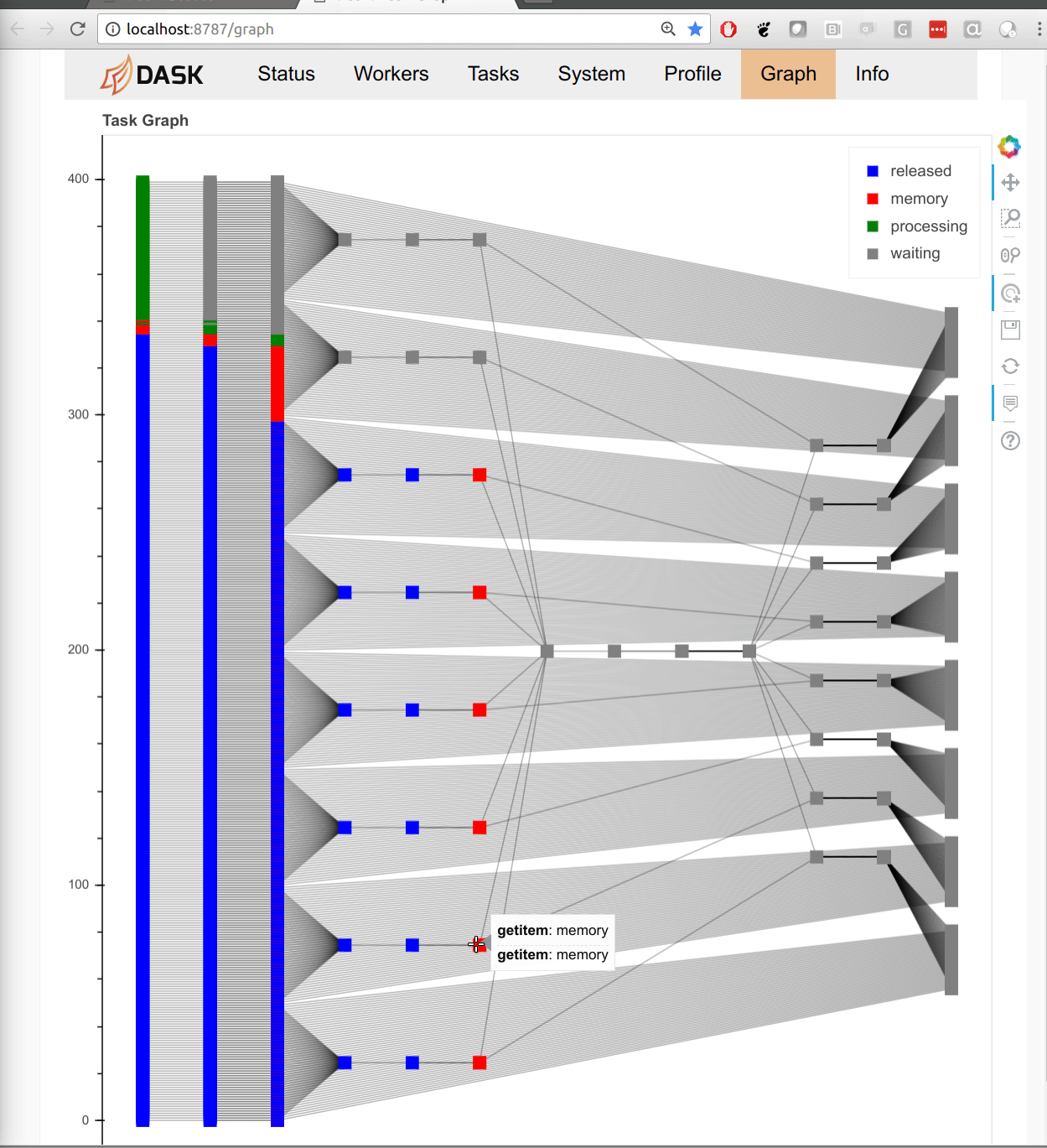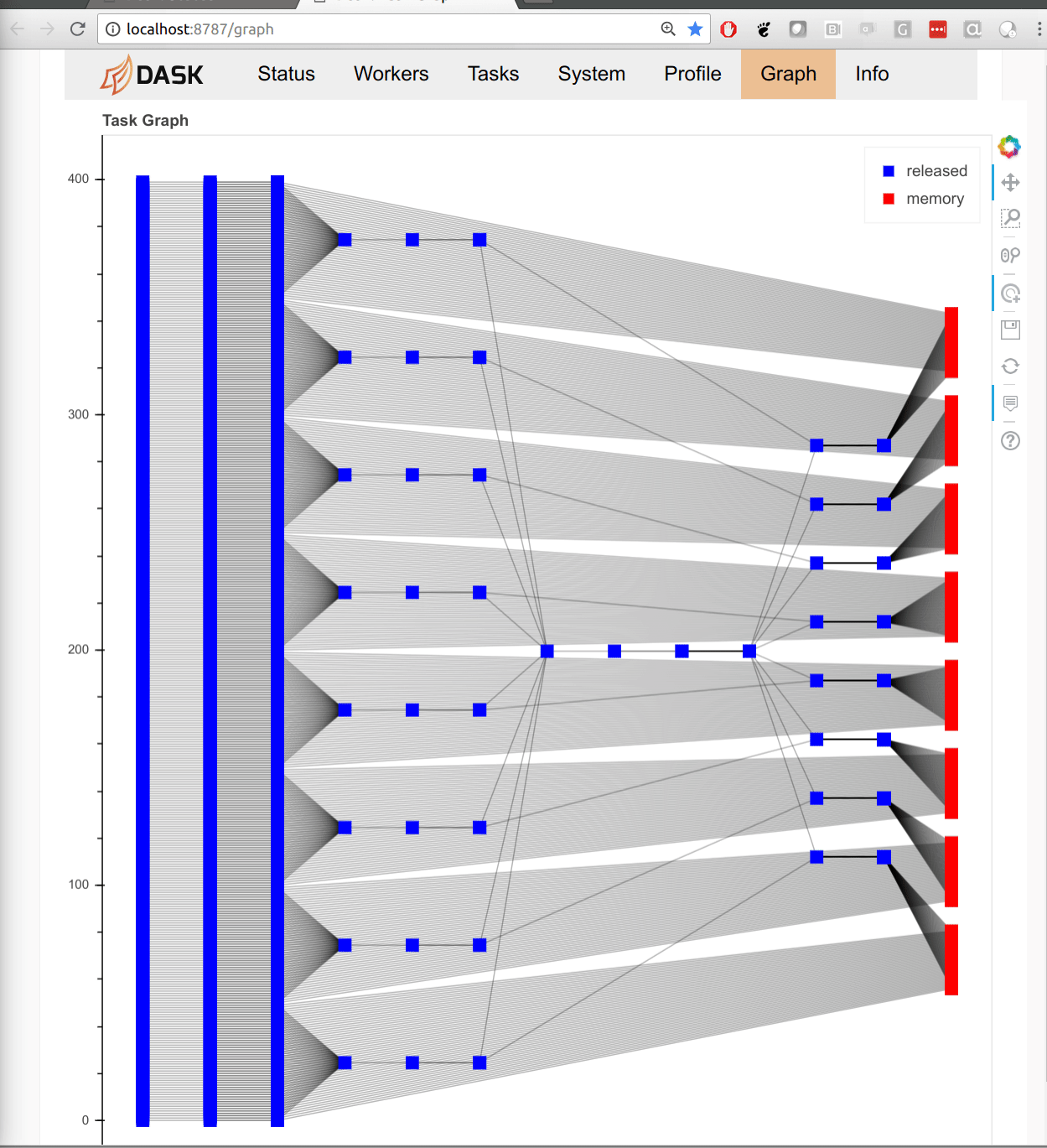
This work is greatly appreciated and was done by Jeremy Chan.
Native support for the Zarr format for chunked n-dimensional arrays landed thanks to Martin Durant and John A Kirkham. Zarr has been especially useful due to its speed, simple spec, support of the full NetCDF style conventions, and amenability to cloud storage.
Dataframes and Pandas 0.23
As usual, Dask Dataframes had many small improvements. Of note is continued compatibility with the just-released Pandas 0.23, and some new data ingestion formats.
Dask.dataframe is consistent with changes in the recent Pandas 0.23 release thanks to Tom Augspurger.
Orc support
Dask.dataframe has grown a reader for the Apache ORC format.
Orc is a format for tabular data storage that is common in the Hadoop ecosystem. The new dd.read_orc function parallelizes around similarly new ORC functionality within PyArrow . Thanks to Jim Crist for the work on the Arrow side and Martin Durant for parallelizing it with Dask.
Read_json support
Dask.dataframe now has also grown a reader for JSON files.
The dd.read_json
function matches most of the pandas.read_json API.
This came about shortly after a recent PyCon 2018 talk comparing Spark and Dask dataframe where Irina Truong mentioned that it was missing. Thanks to Martin Durant and Irina Truong for this contribution.
See the dataframe data ingestion documentation for more information about JSON, ORC, or any of the other formats supported by Dask.dataframe.
Joblib
The Joblib library for parallel computing within Scikit-Learn has had a Dask backend for a while now. While it has always been pretty easy to use, it’s now becoming much easier to use well without much expertise. After using this in practice for a while together with the Scikit-Learn developers, we’ve identified and smoothed over a number of usability issues. These changes will only be fully available after the next Scikit-Learn release (hopefully soon) at which point we’ll probably release a new blogpost dedicated to the topic.
Related projects
This release is timed with the following packages:
- dask
- distributed
- dask-kubernetes
There is also a new repository for deploying applications on YARN (a job scheduler common in Hadoop environments) called skein. Early adopters welcome.
Acknowledgements
Since March 21st, the following people have contributed to the following repositories:
The core Dask repository for parallel algorithms:
- Andrethrill
- Beomi
- Brendan Martin
- Christopher Ren
- Guido Imperiale
- Diane Trout
- fjetter
- Frederick
- Henry Doupe
- James Bourbeau
- Jeremy Chen
- Jim Crist
- John A Kirkham
- Jon Mease
- Jörg Dietrich
- Kevin Mader
- Ksenia Bobrova
- Larsr
- Marc Pfister
- Markus Gonser
- Martin Durant
- Matt Lee
- Matthew Rocklin
- Pierre-Bartet
- Scott Sievert
- Simon Perkins
- Stefan van der Walt
- Stephan Hoyer
- Tom Augspurger
- Uwe L. Korn
- Yu Feng
The dask/distributed repository for distributed computing:
- Bmaisonn
- Grant Jenks
- Henry Doupe
- Irene Rodriguez
- Irina Truong
- John A Kirkham
- Joseph Atkins-Turkish
- Kenneth Koski
- Loïc Estève
- Marius van Niekerk
- Martin Durant
- Matthew Rocklin
- Olivier Grisel
- Russ Bubley
- Tom Augspurger
- Tony Lorenzo
The dask-kubernetes repository for deploying Dask on Kubernetes
- Brendan Martin
- J Gerard
- Matthew Rocklin
- Olivier Grisel
- Yuvi Panda
The dask-jobqueue repository for deploying Dask on HPC job schedulers
- Guillaume Eynard-Bontemps
- jgerardsimcock
- Joseph Hamman
- Loïc Estève
- Matthew Rocklin
- Ray Bell
- Rich Signell
- Shawn Taylor
- Spencer Clark
The dask-ml repository for scalable machine learning:
- Christopher Ren
- Jeremy Chen
- Matthew Rocklin
- Scott Sievert
- Tom Augspurger
Acknowledgements
Thanks to Scott Sievert and James Bourbeau for their help editing this article.
blog comments powered by Disqus