HDF in the Cloud challenges and solutions for scientific data
Multi-dimensional data, such as is commonly stored in HDF and NetCDF formats, is difficult to access on traditional cloud storage platforms. This post outlines the situation, the following possible solutions, and their strengths and weaknesses.
- Cloud Optimized GeoTIFF: We can use modern and efficient formats from other domains, like Cloud Optimized GeoTIFF
- HDF + FUSE: Continue using HDF, but mount cloud object stores as a file system with FUSE
- HDF + Custom Reader: Continue using HDF, but teach it how to read from S3, GCS, ADL, …
- Build a Distributed Service: Allow others to serve this data behind a web API, built however they think best
- New Formats for Scientific Data: Design a new format, optimized for scientific data in the cloud
Not Tabular Data
If your data fits into a tabular format, such that you can use tools like SQL, Pandas, or Spark, then this post is not for you. You should consider Parquet, ORC, or any of a hundred other excellent formats or databases that are well designed for use on cloud storage technologies.
Multi-Dimensional Data
We’re talking about data that is multi-dimensional and regularly strided. This data often occurs in simulation output (like climate models), biomedical imaging (like an MRI scan), or needs to be efficiently accessed across a number of different dimensions (like many complex time series). Here is an image from the popular XArray library to put you in the right frame of mind:
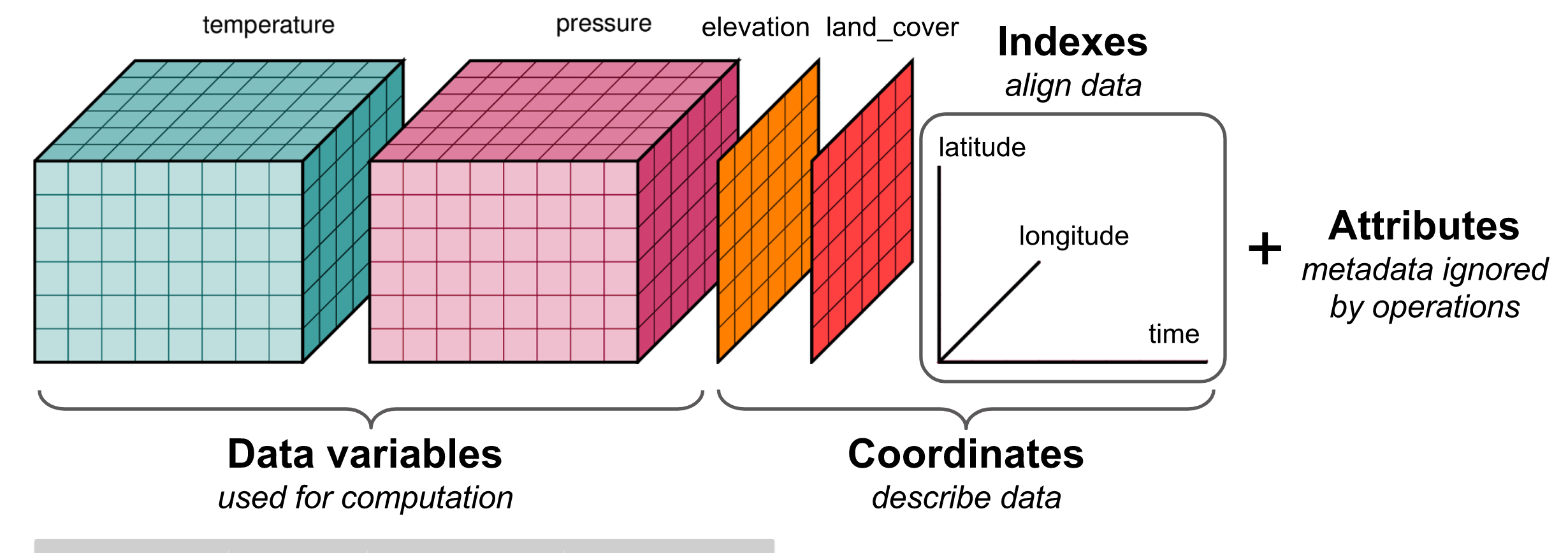
This data is often stored in blocks such that, say, each 100x100x100 chunk of data is stored together, and can be accessed without reading through the rest of the file.
A few file formats allow this layout, the most popular of which is the HDF format, which has been the standard for decades and forms the basis for other scientific formats like NetCDF. HDF is a powerful and efficient format capable of handling both complex hierarchical data systems (filesystem-in-a-file) and efficiently blocked numeric arrays. Unfortunately HDF is difficult to access from cloud object stores (like S3), which presents a challenge to the scientific community.
The Opportunity and Challenge of Cloud Storage
The scientific community generates several petabytes of HDF data annually. Supercomputer simulations (like a large climate model) produce a few petabytes. Planned NASA satellite missions will produce hundreds of petabytes a year of observational data. All of these tend to be stored in HDF.
To increase access, institutions now place this data on the cloud. Hopefully this generates more social value from existing simulations and observations, as they are ideally now more accessible to any researcher or any company without coordination with the host institution.
Unfortunately, the layout of HDF files makes them difficult to query efficiently on cloud storage systems
(like Amazon’s S3, Google’s GCS, or Microsoft’s ADL).
The HDF format is complex and metadata is strewn throughout the file,
so that a complex sequence of reads is required to reach a specific chunk of data.
The only pragmatic way to read a chunk of data from an HDF file today is to use the existing HDF C library,
which expects to receive a C FILE object, pointing to a normal file system
(not a cloud object store) (this is not entirely true, as we’ll see below).
So organizations like NASA are dumping large amounts of HDF onto Amazon’s S3 that no one can actually read, except by downloading the entire file to their local hard drive, and then pulling out the particular bits that they need with the HDF library. This is inefficient. It misses out on the potential that cloud-hosted public data can offer to our society.
The rest of this post discusses a few of the options to solve this problem, including their advantages and disadvantages.
-
Cloud Optimized GeoTIFF: We can use modern and efficient formats from other domains, like Cloud Optimized GeoTIFF
Good: Fast, well established
Bad: Not sophisticated enough to handle some scientific domains
-
HDF + FUSE: Continue using HDF, but mount cloud object stores as a file system with Filesystem in Userspace, aka FUSE
Good: Works with existing files, no changes to the HDF library necessary, useful in non-HDF contexts as well
Bad: It’s complex, probably not performance-optimal, and has historically been brittle
-
HDF + Custom Reader: Continue using HDF, but teach it how to read from S3, GCS, ADL, …
Good: Works with existing files, no complex FUSE tricks
Bad: Requires plugins to the HDF library and tweaks to downstream libraries (like Python wrappers). Will require effort to make performance optimal
-
Build a Distributed Service: Allow others to serve this data behind a web API, built however they think best
Good: Lets other groups think about this problem and evolve complex backend solutions while maintaining stable frontend API
Bad: Complex to write and deploy. Probably not free. Introduces an intermediary between us and our data.
-
New Formats for Scientific Data: Design a new format, optimized for scientific data in the cloud
Good: Fast, intuitive, and modern
Bad: Not a community standard
Now we discuss each option in more depth.
Use Other Formats, like Cloud Optimized GeoTIFF
We could use formats other than HDF and NetCDF that are already well established. The two that I hear most often proposed are Cloud Optimized GeoTIFF and Apache Parquet. Both are efficient, well designed for cloud storage, and well established as community standards. If you haven’t already, I strongly recommend reading Chris Holmes’ (Planet) blog series on Cloud Native Geospatial.
These formats are well designed for cloud storage because they support random access well with relatively few communications and with relatively simple code.
If you needed to you could look at the Cloud Optimized GeoTIFF spec,
and within an hour of reading,
get an image that you wanted using nothing but a few curl commands.
Metadata is in a clear centralized place.
That metadata provides enough information to issue further commands to get the relevant bytes from the object store.
Those bytes are stored in a format that is easily interpreted by a variety of common tools across all platforms.
However, neither of these formats are sufficiently expressive to handle some of the use cases of HDF and NetCDF. Recall our image earlier about atmospheric data:
Our data isn’t a parquet table, nor is it a stack of geo-images. While it’s true that you could store any data in these formats, for example by saving each horizontal slice as a GeoTIFF, or each spatial point as a row in a Parquet table, these storage layouts would be inefficient for regular access patterns. Some parts of the scientific community need blocked layouts for multi-dimensional array data.
HDF and Filesystems in Userspace (FUSE)
We could access HDF data on the cloud now if we were able to convince our operating system that S3 or GCS or ADL were a normal file system. This is a reasonable goal; cloud object stores look and operate much like normal file systems. They have directories that you can list and navigate. They have files/objects that you can copy, move, rename, and from which you can read or write small sections.
We can achieve this using an operating systems trick, FUSE, or Filesystem in Userspace. This allows us to make a program that the operating system treats as a normal file system. Several groups have already done this for a variety of cloud providers. Here is an example with the gcsfs Python library
$ pip install gcsfs --upgrade
$ mkdir /gcs
$ gcsfuse bucket-name /gcs --background
Mounting bucket bucket-name to directory /gcs
$ ls /gcs
my-file-1.hdf
my-file-2.hdf
my-file-3.hdf
...
Now we point our HDF library to a NetCDF file in that directory
(which actually points to an object on Google Cloud Storage),
and it happily uses C File objects to read and write data.
The operating system passes the read/write requests to gcsfs,
which goes out to the cloud to get data, and then hands it back to the operating system, which hands it to HDF.
All normal HDF operations just work,
although they may now be significantly slower.
The cloud is further away than local disk.
This slowdown is significant because the HDF library makes many small 4kB reads in order to gather the metadata necessary to pull out a chunk of data. Each of those tiny reads made sense when the data was local, but now that we’re sending out a web request each time. This means that users can sit for minutes just to open a file.
Fortunately, we can be clever. By buffering and caching data, we can reduce the number of web requests. For example, when asked to download 4kB we actually download 100kB or 1MB. If some of the future 4kB reads are within this 1MB then we can return them immediately., Looking at HDF traces it looks like we can probably reduce “dozens” of web requests to “a few”.
FUSE also requires elevated operating system permissions, which can introduce challenges if working from Docker containers (which is likely on the cloud). Docker containers running FUSE need to be running in privileged mode. There are some tricks around this, but generally FUSE brings some excess baggage.
HDF and a Custom Reader
The HDF library doesn’t need to use C File pointers, we can extend it to use other storage backends as well. Virtual File Layers are an extension mechanism within HDF5 that could allow it to target cloud object stores. This has already been done to support Amazon’s S3 object store twice:
- Once by the HDF group, S3VFD (currently private),
- Once by Joe Jevnik and Scott Sanderson (Quantopian) at https://h5s3.github.io/h5s3/ (highly experimental)
This provides an alternative to FUSE that is better because it doesn’t require privileged access, but is worse because it only solves this problem for HDF and not all file access.
In either case we’ll need to do look-ahead buffering and caching to get reasonable performance (or see below).
Centralize Metadata
Alternatively, we might centralize metadata in the HDF file in order to avoid many hops throughout that file. This would remove the need to perform clever file-system caching and buffering tricks.
Here is a brief technical explanation from Joe Jevnik:
Regarding the centralization of metadata: this is already a feature of hdf5 and is used by many of the built-in drivers. This optimization is enabled by setting the
H5FD_FEAT_AGGREGATE_METADATAandH5FD_FEAT_ACCUMULATE_METADATAfeature flags in your VFL driver’s query function. The first flag says that the hdf5 library should pre-allocate a large region to store metadata, future metadata allocations will be served from this pool. The second flag says that the library should buffer metadata changes into large chunks before dispatching the VFL driver’s write function. Both the default driver (sec2) and h5s3 enable these optimizations. This is further supported by using theH5FD_FLMAP_DICHOTOMYfree list option which uses one free list for metadata allocations and another for non-metadata allocations. If you really want to ensure that the metadata is aggregated, even without a repack, you can use the built-in ‘multi’ driver which dispatches different allocation flavors to their own driver.
Distributed Service
We could offload this problem to a company, like the non-profit HDF group or a for-profit cloud provider like Google, Amazon, or Microsoft. They would solve this problem however they like, and expose a web API that we can hit for our data.
This would be a distributed service of several computers on the cloud near our data, that takes our requests for what data we want, perform whatever tricks they deem appropriate to get that data, and then deliver it to us. This fleet of machines will still have to address the problems listed above, but we can let them figure it out, and presumably they’ll learn as they go.
However, this has both technical and social costs. Technically this is complex, and they’ll have to handle a new set of issues around scalability, consistency, and so on that are already solved(ish) in the cloud object stores. Socially this creates an intermediary between us and our data, which we may not want both for reasons of cost and trust.
The HDF group is working on such a service, HSDS that works on Amazon’s S3 (or anything that looks like S3). They have created a h5pyd library that is a drop-in replacement for the popular h5py Python library.
Presumably a cloud provider, like Amazon, Google, or Microsoft could do this as well. By providing open standards like OpenDAP they might attract more science users onto their platform to more efficiently query their cloud-hosted datasets.
The satellite imagery company Planet already has such a service.
New Formats for Scientific Data
Alternatively, we can move on from the HDF file format, and invent a new data storage specification that fits cloud storage (or other storage) more cleanly without worrying about supporting the legacy layout of existing HDF files.
This has already been going on, informally, for years. Most often we see people break large arrays into blocks, store each block as a separate object in the cloud object store with a suggestive name, and store a metadata file describing how the blocks relate to each other. This looks something like the following:
/metadata.json
/0.0.0.dat
/0.0.1.dat
/0.0.2.dat
...
/10.10.8.dat
/10.10.9.dat
/10.10.10.dat
There are many variants:
- They might extend this to have groups or sub-arrays in sub-directories.
- They might choose to compress the individual blocks in the
.datfiles or not. - They might choose different encoding schemes for the metadata and the binary blobs.
But generally most array people on the cloud do something like this with their research data, and they’ve been doing it for years. It works efficiently, is easy to understand and manage, and transfers well to any cloud platform, onto a local file system, or even into a standalone zip file or small database.
There are two groups that have done this in a more mature way, defining both modular standalone libraries to manage their data, as well as proper specification documents that inform others how to interpret this data in a long-term stable way.
These are both well maintained and well designed libraries (by my judgment), in Python and Java respectively. They offer layouts like the layout above, although with more sophistication. Entertainingly their specs are similar enough that another library, Z5, built a cross-compatible parser for each in C++. This unintended uniformity is a good sign. It means that both developer groups were avoiding creativity, and have converged on a sensible common solution. I encourage you to read the Zarr Spec in particular.
However, technical merits are not alone sufficient to justify a shift in data format, especially for archival datasets of record that we’re discussing. The institutions in charge of this data and have multi-decade horizons and so move slowly. For them, moving off of the historically community standard would be major shift.
And so we need to answer a couple of difficult questions:
- How hard is it to make HDF efficient in the cloud?
- How hard is it to shift the community to a new standard?
A Sense of Urgency
These questions are important now. NASA and other agencies are pushing NetCDF data into the Cloud today and will be increasing these rates substantially in the coming years.
From earthdata.nasa.gov/cmr-and-esdc-in-cloud (via Ryan Abernathey)
From its current cumulative archive size of almost 22 petabytes (PB), the volume of data in the EOSDIS archive is expected to grow to almost 247 PB by 2025, according to estimates by NASA’s Earth Science Data Systems (ESDS) Program. Over the next five years, the daily ingest rate of data into the EOSDIS archive is expected to reach 114 terabytes (TB) per day, with the upcoming joint NASA/Indian Space Research Organization Synthetic Aperture Radar (NISAR) mission (scheduled for launch by 2021) contributing an estimated 86 TB per day of data when operational.
This is only one example of many agencies in many domains pushing scientific data to the cloud.
Acknowledgements
Thanks to Joe Jevnik (Quantopian), John Readey (HDF Group), Rich Signell (USGS), and Ryan Abernathey (Columbia University) for their feedback when writing this article. This conversation started within the Pangeo collaboration.
blog comments powered by Disqus