Dask Release 0.16.0
This work is supported by Anaconda Inc. and the Data Driven Discovery Initiative from the Moore Foundation.
I’m pleased to announce the release of Dask version 0.16.0. This is a major release with new features, breaking changes, and stability improvements. This blogpost outlines notable changes since the 0.15.3 release on September 24th.
You can conda install Dask:
conda install dask
or pip install from PyPI:
pip install dask[complete] --upgrade
Conda packages are available on both conda-forge and default channels.
Full changelogs are available here:
Some notable changes follow.
Breaking Changes
- The
dask.asyncmodule was moved todask.localfor Python 3.7 compatibility. This was previously deprecated and is now fully removed. - The distributed scheduler’s diagnostic JSON pages have been removed and replaced by more informative templated HTML.
- The use of commonly-used private methods
_keysand_optimizehave been replaced with the Dask collection interface (see below).
Dask collection interface
It is now easier to implement custom collections using the Dask collection interface.
Dask collections (arrays, dataframes, bags, delayed) interact with Dask
schedulers (single-machine, distributed) with a few internal methods. We
formalized this interface into protocols like .__dask_graph__() and
.__dask_keys__() and have
published that interface.
Any object that implements the methods described in that document will interact
with all Dask scheduler features as a first-class Dask object.
class MyDaskCollection(object):
def __dask_graph__(self):
...
def __dask_keys__(self):
...
def __dask_optimize__(self, ...):
...
...
This interface has already been implemented within the XArray project for labeled and indexed arrays. Now all XArray classes (DataSet, DataArray, Variable) are fully understood by all Dask schedulers. They are as first-class as dask.arrays or dask.dataframes.
import xarray as xa
from dask.distributed import Client
client = Client()
ds = xa.open_mfdataset('*.nc', ...)
ds = client.persist(ds) # XArray object integrate seamlessly with Dask schedulers
- Documentation: http://dask.pydata.org/en/latest/custom-collections.html
Work on Dask’s collection interfaces was primarily done by Jim Crist.
Bandwidth and Tornado 5 compatibility
Dask is built on the Tornado library for concurrent network programming. In an effort to improve inter-worker bandwidth on exotic hardware (Infiniband), Dask developers are proposing changes to Tornado’s network infrastructure.
However, in order to use these changes Dask itself needs to run on the next version of Tornado in development, Tornado 5.0.0, which breaks a number of interfaces on which Dask has relied. Dask developers have been resolving these and we encourage other PyData developers to do the same. For example, neither Bokeh nor Jupyter work on Tornado 5.0.0-dev.
Dask inter-worker bandwidth is peaking at around 1.5-2GB/s on a network theoretically capable of 3GB/s. GitHub issue: pangeo #6
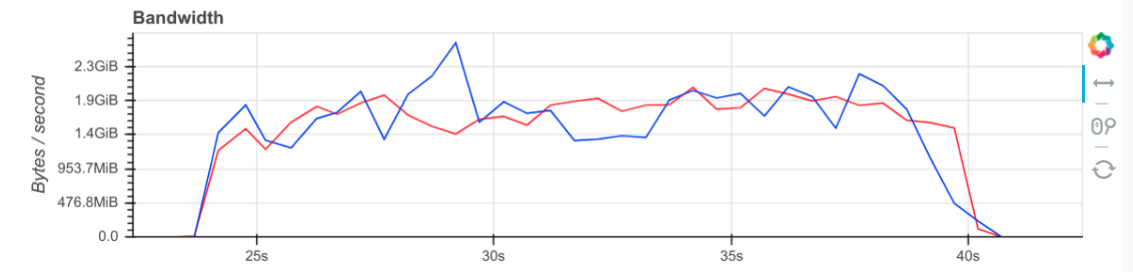
Network performance and Tornado compatibility are primarily being handled by Antoine Pitrou.
Parquet Compatibility
Dask.dataframe can use either of the two common Parquet libraries in Python, Apache Arrow and Fastparquet. Each has its own strengths and its own base of users who prefer it. We’ve significantly extended Dask’s parquet test suite to cover each library, extending roundtrip compatibility. Notably, you can now both read and write with PyArrow.
df.to_parquet('...', engine='fastparquet')
df = dd.read_parquet('...', engine='pyarrow')
There is still work to be done here. The variety of parquet reader/writers and conventions out there makes completely solving this problem difficult. It’s nice seeing the various projects slowly converge on common functionality.
This work was jointly done by Uwe Korn, Jim Crist, and Martin Durant.
Retrying Tasks
One of the most requested features for the Dask.distributed scheduler is the ability to retry failed tasks. This is particularly useful to people using Dask as a task queue, rather than as a big dataframe or array.
future = client.submit(func, *args, retries=5)
Task retries were primarily built by Antoine Pitrou.
Transactional Work Stealing
The Dask.distributed task scheduler performs load balancing through work stealing. Previously this would sometimes result in the same task running simultaneously in two locations. Now stealing is transactional, meaning that it will avoid accidentally running the same task twice. This behavior is especially important for people using Dask tasks for side effects.
It is still possible for the same task to run twice, but now this only happens in more extreme situations, such as when a worker dies or a TCP connection is severed, neither of which are common on standard hardware.
Transactional work stealing was primarily implemented by Matthew Rocklin.
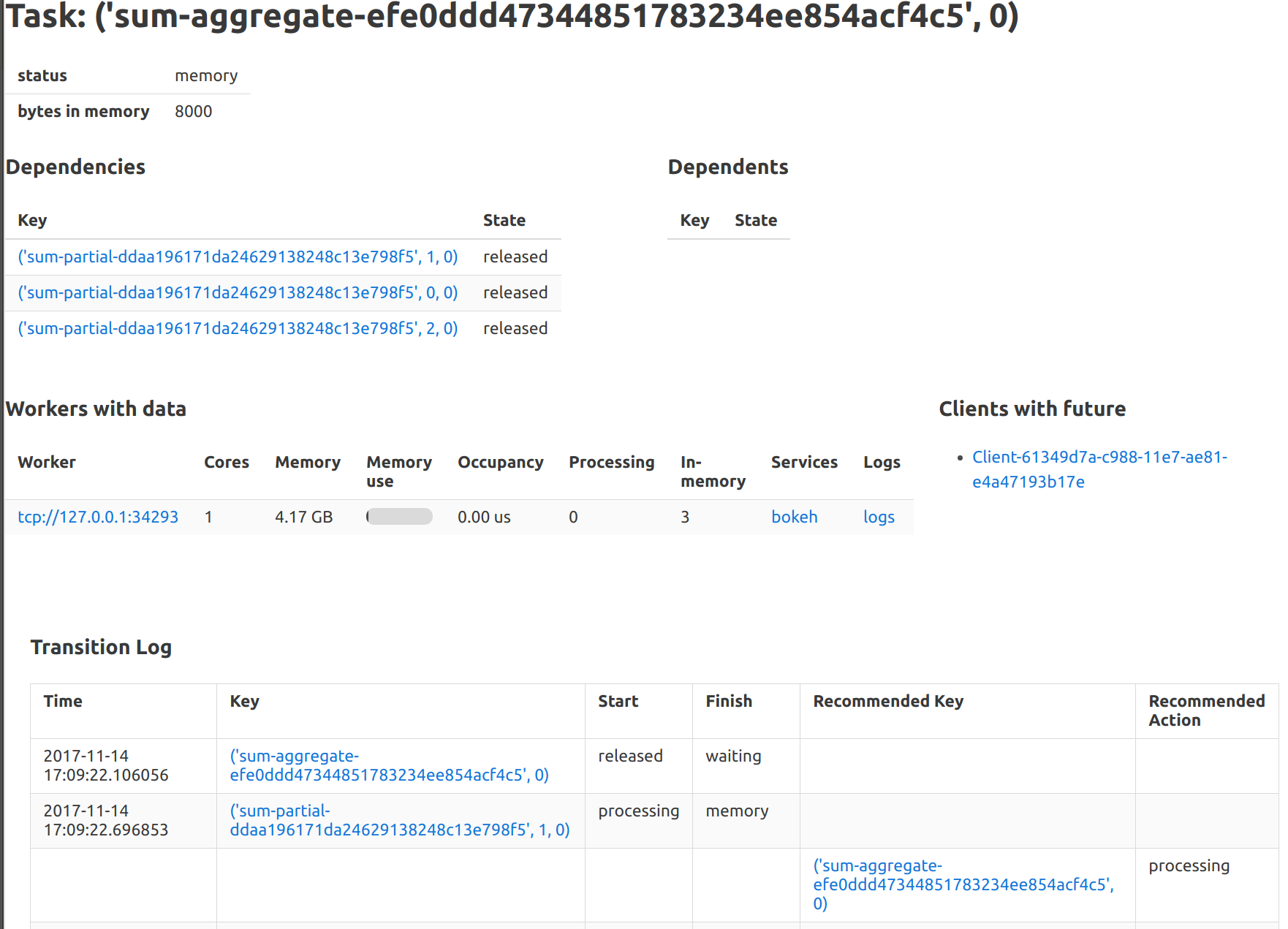
New Diagnostic Pages
There is a new set of diagnostic web pages available in the Info tab of the dashboard. These pages provide more in-depth information about each worker and task, but are not dynamic in any way. They use Tornado templates rather than Bokeh plots, which means that they are less responsive but are much easier to build. This is an easy and cheap way to expose more scheduler state.
Nested compute calls
Calling .compute() within a task now invokes the same distributed
scheduler. This enables writing more complex workloads with less thought to
starting worker clients.
import dask
from dask.distributed import Client
client = Client() # only works for the newer scheduler
@dask.delayed
def f(x):
...
return dask.compute(...) # can call dask.compute within delayed task
dask.compute([f(i) for ...])
Nested compute calls were primarily developed by Matthew Rocklin and Olivier Grisel.
More aggressive Garbage Collection
The workers now explicitly call gc.collect() at various times when under
memory pressure and when releasing data. This helps to avoid some memory
leaks, especially when using Pandas dataframes. Doing this carefully proved
to require a surprising degree of detail.
Improved garbage collection was primarily implemented and tested by Fabian Keller and Olivier Grisel, with recommendations by Antoine Pitrou.
Related projects
Dask-ML
A variety of Dask Machine Learning projects are now being assembled under one unified repository, dask-ml. We encourage users and researchers alike to read through that project. We believe there are many useful and interesting approaches contained within.
- Docs: dask-ml.readthedocs.io
- Github: github.com/dask/dask-ml
The work to assemble and curate these algorithms is primarily being handled by Tom Augspurger.
XArray
The XArray project for indexed and labeled arrays is also releasing their major 0.10.0 release this week, which includes many performance improvements, particularly for using Dask on larger datasets.
- Docs: xarray.pydata.org
- Release notes: xarray.pydata.org/en/latest/whats-new.html
Acknowledgements
The following people contributed to the dask/dask repository since the 0.15.3 release on September 24th:
- Ced4
- Christopher Prohm
- fjetter
- Hai Nguyen Mau
- Ian Hopkinson
- James Bourbeau
- James Munroe
- Jesse Vogt
- Jim Crist
- John Kirkham
- Keisuke Fujii
- Matthias Bussonnier
- Matthew Rocklin
- mayl
- Martin Durant
- Olivier Grisel
- severo
- Simon Perkins
- Stephan Hoyer
- Thomas A Caswell
- Tom Augspurger
- Uwe L. Korn
- Wei Ji
- xwang777
The following people contributed to the dask/distributed repository since the 1.19.1 release on September 24nd:
- Alvaro Ulloa
- Antoine Pitrou
- chkoar
- Fabian Keller
- Ian Hopkinson
- Jim Crist
- Kelvin Yang
- Krisztián Szűcs
- Matthew Rocklin
- Mike DePalatis
- Olivier Grisel
- rbubley
- Tom Augspurger
The following people contributed to the dask/dask-ml repository
- Evan Welch
- Matthew Rocklin
- severo
- Tom Augspurger
- Trey Causey
In addition, we are proud to announce that Olivier Grisel has accepted commit rights to the Dask projects. Olivier has been particularly active on the distributed scheduler, and on related projects like Joblib, SKLearn, and Cloudpickle.
blog comments powered by Disqus