Introducing PyToolz a functional standard library
The PyToolz project extends itertools and functools to provide a set of
standard functions for iterators, functions, and dictionaries.
tl;dr – PyToolz provides good functions for core data structures. These functions work together well. Here is a partial API:
groupby, unique, isiterable, intersection, frequencies,
get, concat, isdistinct, interleave, accumulate
first, second, nth, take, drop, rest, last,
memoize, curry, compose, merge, assoc
Why?
Two years ago I started playing with functional programming. One powerful feature of functional languages oddly stuck out as having very little to do with FP in general. In particular modern functional languages often have really killer standard libraries for dealing with iterators, functions, and dictionaries. This standard function set doesn’t depend on macros, monads, or any other mind bending language feature understandable only to LISP-ers or Haskell-ites. This feature only requires higher order functions and lazy iterators, both of which Python does quite well.
This is well known. The libraries itertools and functools are supposed to
fill this niche in the Python ecosystem. Personally I’ve found these libraries
to be useful but often incomplete (although the Python 3 versions are
showing signs of improvement.) To fill these gaps we started hacking together
the libraries itertoolz and functoolz which were modeled largely after the
Clojure standard library. These projects were
eventually merged into a single codebase, named toolz which is available for
your hacking pleasure at
http://github.com/pytoolz/toolz/.
Official
The official description of Toolz from the docs is as follows:
The Toolz project provides a set of utility functions for iterators, functions,
and dictionaries. These functions are designed to interoperate well, forming
the building blocks of common data analytic operations. They extend the
standard libraries itertools and functools and borrow heavily from the
standard libraries of contemporary functional languages.
Toolz provides a suite of functions which have the following virtues:
- Composable: They interoperate due to their use of core data structures.
- Pure: They don’t change their inputs or rely on external state.
- Lazy: They don’t run until absolutely necessary, allowing them to support large streaming data sets.
This gives developers the power to write powerful programs to solve complex problems with relatively simple code which is easy to understand without sacrificing performance. Toolz enables this approach, commonly associated with functional programming, within a natural Pythonic style suitable for most developers.
This project follows in the footsteps of the popular projects Underscore.js
for JavaScript and and Enumerable for Ruby.
Examples
Word counting is a common example used to show off data processing libraries.
The Python version that leverages toolz demonstrates how the algorithm can be
deconstructed into the three operations of splitting, stemming, and frequency
counting:
>>> from toolz import *
>>> def stem(word):
... """ Stem word to primitive form """
... return word.lower().rstrip(",.!:;'-\"").lstrip("'\"")
>>> wordcount = compose(frequencies, partial(map, stem), str.split) # Function
>>> sentence = "This cat jumped over this other cat!" # Data
>>> wordcount(sentence)
{'this': 2, 'cat': 2, 'jumped': 1, 'over': 1, 'other': 1}There are many solutions to the wordcounting problem. What I like about this solution is that it breaks down the wordcounting problem into a composition of three fundamental operations.
- Splitting a text into words – (
str.split) - Stemming those words to a base form so that
'Hello!'is the same as'hello'– (partial(map, stem)) - Counting occurrences of each base word – (
frequencies)
Toolz provides both common operations for iterators (like frequencies for
counting occurrences) and common operations for functions (like compose for
function composition). Using these together, programmers can describe a
number of data analytic solutions clearly and concisely.
Here is another example performing analytics on the following directed graph
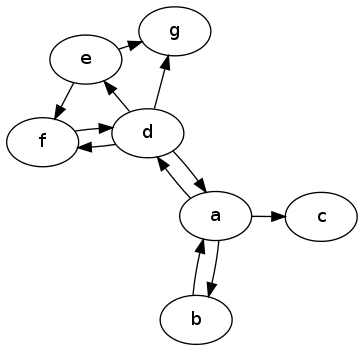
>>> from toolz.curried import *
>>> a, b, c, d, e, f, g = 'abcdefg'
>>> edges = [(a, b), (b, a), (a, c), (a, d), (d, a), (d, e),
... (e, f), (d, f), (f, d), (d, g), (e, g)]
>>> # Nodes
>>> set(concat(edges))
{'a', 'b', 'c', 'd', 'e', 'f', 'g'}
>>> # Out degree
>>> countby(first, edges)
{'a': 3, 'b': 1, 'd': 4, 'e': 2, 'f': 1}
>>> # In degree
>>> countby(second, edges)
{'a': 2, 'b': 1, 'c': 1, 'd': 2, 'e': 1, 'f': 2, 'g': 2}
>>> # Out neighbors
>>> valmap(compose(list, map(second)),
... groupby(first, edges))
{'a': ['b', 'c', 'd'],
'b': ['a'],
'd': ['a', 'e', 'f', 'g'],
'e': ['f', 'g'],
'f': ['d']}
>>> # In neighbors
>>> valmap(compose(list, map(first)),
... groupby(second, edges))
{'a': ['b', 'd'],
'b': ['a'],
'c': ['a'],
'd': ['a', 'f'],
'e': ['d'],
'f': ['e', 'd'],
'g': ['d', 'e']}Learning a small set of higher order functions like groupby, map, and
valmap gives a surprising amount of leverage over this kind of data.
Additionally the streaming nature of many (but not all) of the algorithms
allows toolz to perform well even on datasets that do not fit comfortably
into memory.
I routinely process large network datasets at my work and find toolz to be
invaluable in this context.
For More Information
-
Documentation is available at http://toolz.readthedocs.org/
-
BSD licensed source code is available at http://github.com/pytoolz/toolz/
-
The API is thoroughly documented at http://toolz.readthedocs.org/en/latest/api.html
-
toolzispip/easy_installable. It supports Python 2.6-3.3 and depends only on the standard library.
blog comments powered by Disqus