Pickle isn't slow, it's a protocol
This work is supported by Anaconda Inc
tl;dr: Pickle isn’t slow, it’s a protocol. Protocols are important for ecosystems.
A recent Dask issue showed that using Dask with PyTorch was slow because sending PyTorch models between Dask workers took a long time (Dask GitHub issue).
This turned out to be because serializing PyTorch models with pickle was very slow (1 MB/s for GPU based models, 50 MB/s for CPU based models). There is no architectural reason why this needs to be this slow. Every part of the hardware pipeline is much faster than this.
We could have fixed this in Dask by special-casing PyTorch models (Dask has it’s own optional serialization system for performance), but being good ecosystem citizens, we decided to raise the performance problem in an issue upstream (PyTorch Github issue). This resulted in a five-line-fix to PyTorch that turned a 1-50 MB/s serialization bandwidth into a 1 GB/s bandwidth, which is more than fast enough for many use cases (PR to PyTorch).
def __reduce__(self):
- return type(self), (self.tolist(),)
+ b = io.BytesIO()
+ torch.save(self, b)
+ return (_load_from_bytes, (b.getvalue(),))
+def _load_from_bytes(b):
+ return torch.load(io.BytesIO(b))
Thanks to the PyTorch maintainers this problem was solved pretty easily. PyTorch tensors and models now serialize efficiently in Dask or in any other Python library that might want to use them in distributed systems like PySpark, IPython parallel, Ray, or anything else without having to add special-case code or do anything special. We didn’t solve a Dask problem, we solved an ecosystem problem.
However before we solved this problem we discussed things a bit. This comment stuck with me:
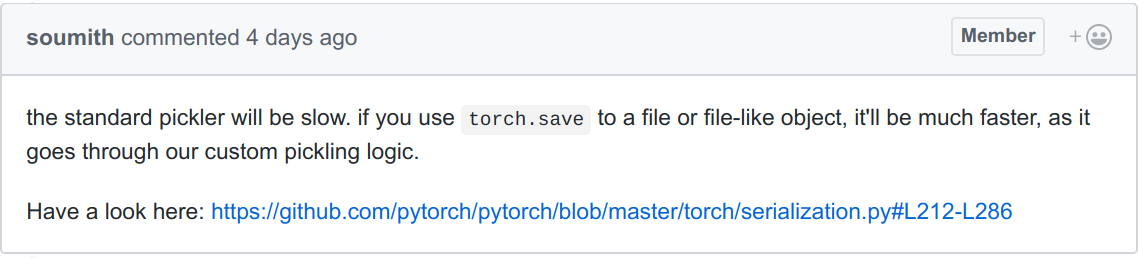
This comment contains two beliefs that are both very common, and that I find somewhat counter-productive:
- Pickle is slow
- You should use our specialized methods instead
I’m sort of picking on the PyTorch maintainers here a bit (sorry!) but I’ve found that they’re quite widespread, so I’d like to address them here.
Pickle is slow
Pickle is not slow. Pickle is a protocol. We implement pickle. If it’s slow then it is our fault, not Pickle’s.
To be clear, there are many reasons not to use Pickle.
- It’s not cross-language
- It’s not very easy to parse
- It doesn’t provide random access
- It’s insecure
- etc..
So you shouldn’t store your data or create public services using Pickle, but for things like moving data on a wire it’s a great default choice if you’re moving strictly from Python processes to Python processes in a trusted and uniform environment.
It’s great because it’s as fast as you can make it (up a a memory copy) and other libraries in the ecosystem can use it without needing to special case your code into theirs.
This is the change we did for PyTorch.
def __reduce__(self):
- return type(self), (self.tolist(),)
+ b = io.BytesIO()
+ torch.save(self, b)
+ return (_load_from_bytes, (b.getvalue(),))
+def _load_from_bytes(b):
+ return torch.load(io.BytesIO(b))
The slow part wasn’t Pickle, it was the .tolist() call within __reduce__
that converted a PyTorch tensor into a list of Python ints and floats. I
suspect that the common belief of “Pickle is just slow” stopped anyone else
from investigating the poor performance here. I was surprised to learn that a
project as active and well maintained as PyTorch hadn’t fixed this already.
As a reminder, you can implement the pickle protocol by providing the
__reduce__ method on your class. The __reduce__ function returns a
loading function and sufficient arguments to reconstitute your object. Here we
used torch’s existing save/load functions to create a bytestring that we could
pass around.
Just use our specialized option
Specialized options can be great. They can have nice APIs with many options, they can tune themselves to specialized communication hardware if it exists (like RDMA or NVLink), and so on. But people need to learn about them first, and learning about them can be hard in two ways.
Hard for users
Today we use a large and rapidly changing set of libraries. It’s hard for users to become experts in all of them. Increasingly we rely on new libraries making it easy for us by adhering to standard APIs, providing informative error messages that lead to good behavior, and so on..
Hard for other libraries
Other libraries that need to interact definitely won’t read the documentation, and even if they did it’s not sensible for every library to special case every other library’s favorite method to turn their objects into bytes. Ecosystems of libraries depend strongly on the presence of protocols and a strong consensus around implementing them consistently and efficiently.
Sometimes Specialized Options are Appropriate
There are good reasons to support specialized options. Sometimes you need more than 1GB/s bandwidth. While this is rare in general (very few pipelines process faster than 1GB/s/node), it is true in the particular case of PyTorch when they are doing parallel training on a single machine with multiple processes. Soumith (PyTorch maintainer) writes the following:
When sending Tensors over multiprocessing, our custom serializer actually shortcuts them through shared memory, i.e. it moves the underlying Storages to shared memory and restores the Tensor in the other process to point to the shared memory. We did this for the following reasons:
-
Speed: we save on memory copies, especially if we amortize the cost of moving a Tensor to shared memory before sending it into the multiprocessing Queue. The total cost of actually moving a Tensor from one process to another ends up being O(1), and independent of the Tensor’s size
-
Sharing: If Tensor A and Tensor B are views of each other, once we serialize and send them, we want to preserve this property of them being views. This is critical for neural-nets where it’s common to re-view the weights / biases and use them for another. With the default pickle solution, this property is actually lost.
blog comments powered by Disqus