Dask Release 0.17.2
This work is supported by Anaconda Inc. and the Data Driven Discovery Initiative from the Moore Foundation.
I’m pleased to announce the release of Dask version 0.17.2. This is a minor release with new features and stability improvements. This blogpost outlines notable changes since the 0.17.0 release on February 12th.
You can conda install Dask:
conda install dask
or pip install from PyPI:
pip install dask[complete] --upgrade
Full changelogs are available here:
Some notable changes follow:
Tornado 5.0
Tornado is a popular framework for concurrent network programming that Dask relies on heavily. Tornado recently released a major version update that included both some major features for Dask as well as a couple of bugs.
The new IOStream.read_into method allows Dask communications (or anyone using
this API) to move large datasets more efficiently over the network with
fewer copies. This enables Dask to take advantage of high performance
networking available on modern super-computers. On the Cheyenne system, where
we tested this, we were able to get the full 3GB/s bandwidth available through
the Infiniband network with this change (when using a few worker processes).
Many thanks to Antoine Pitrou and Ben Darnell for their efforts on this.
At the same time there were some unforeseen issues in the update to Tornado 5.0.
More pervasive use of bytearrays over bytes caused issues with compression
libraries like Snappy and Python 2 that were not expecting these types. There
is a brief window in distributed.__version__ == 1.21.3 that enables this
functionality if Tornado 5.0 is present but will misbehave if Snappy is also
present.
HTTP File System
Dask leverages a file-system-like protocol for access to remote data. This is what makes commands like the following work:
import dask.dataframe as dd
df = dd.read_parquet('s3://...')
df = dd.read_parquet('hdfs://...')
df = dd.read_parquet('gcs://...')
We have now added http and https file systems for reading data directly from web servers. These also support random access if the web server supports range queries.
df = dd.read_parquet('https://...')
As with S3, HDFS, GCS, … you can also use these tools outside of Dask development. Here we read the first twenty bytes of the Pandas license:
from dask.bytes.http import HTTPFileSystem
http = HTTPFileSystem()
with http.open('https://raw.githubusercontent.com/pandas-dev/pandas/master/LICENSE') as f:
print(f.read(20))
b'BSD 3-Clause License'
Thanks to Martin Durant who did this work and manages Dask’s byte handling generally. See remote data documentation for more information.
Fixed a correctness bug in Dask dataframe’s shuffle
We identified and resolved a correctness bug in dask.dataframe’s shuffle that resulted in some rows being dropped during complex operations like joins and groupby-applies with many partitions.
See dask/dask #3201 for more information.
Cluster super-class and intelligent adaptive deployments
There are many Python subprojects that help you deploy Dask on different
cluster resource managers like Yarn, SGE, Kubernetes, PBS, and more. These
have all converged to have more-or-less the same API that we have now combined
into a consistent interface that downstream projects can inherit from in
distributed.deploy.Cluster.
Now that we have a consistent interface we have started to invest more in improving the interface and intelligence of these systems as a group. This includes both pleasant IPython widgets like the following:
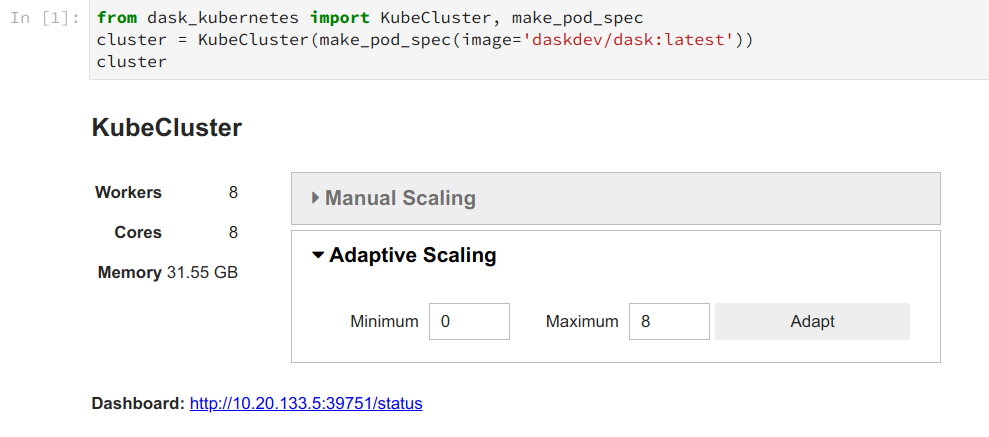
as well as improved logic around adaptive deployments. Adaptive deployments allow clusters to scale themselves automatically based on current workload. If you have recently submitted a lot of work the scheduler will estimate its duration and ask for an appropriate number of workers to finish the computation quickly. When the computation has finished the scheduler will release the workers back to the system to free up resources.
The logic here has improved substantially including the following:
- You can specify minimum and maximum limits on your adaptivity
- The scheduler estimates computation duration and asks for workers appropriately
- There is some additional delay in giving back workers to avoid hysteresis, or cases where we repeatedly ask for and return workers
Related projects
Some news from related projects:
- The young daskernetes project was renamed to dask-kubernetes. This displaces a previous project (that had not been released) for launching Dask on Google Cloud Platform. That project has been renamed to dask-gke.
- A new project, dask-jobqueue was started to handle launching Dask clusters on traditional batch queuing systems like PBS, SLURM, SGE, TORQUE, etc.. This projet grew out of the Pangeo collaboration
- A Dask Helm chart has been added to Helm’s stable channel
Acknowledgements
The following people contributed to the dask/dask repository since the 0.17.0 release on February 12h:
- Anderson Banihirwe
- Dan Collins
- Dieter Weber
- Gabriele Lanaro
- John Kirkham
- James Bourbeau
- Julien Lhermitte
- Matthew Rocklin
- Martin Durant
- Max Epstein
- nkhadka
- okkez
- Pangeran Bottor
- Rich Postelnik
- Scott M. Edenbaum
- Simon Perkins
- Thrasibule
- Tom Augspurger
- Tor E Hagemann
- Uwe L. Korn
- Wes Roach
The following people contributed to the dask/distributed repository since the 1.21.0 release on February 12th:
- Alexander Ford
- Andy Jones
- Antoine Pitrou
- Brett Naul
- Joe Hamman
- John Kirkham
- Loïc Estève
- Matthew Rocklin
- Matti Lyra
- Sven Kreiss
- Thrasibule
- Tom Augspurger
blog comments powered by Disqus