Distributed Scheduling
This work is supported by Continuum Analytics and the XDATA Program as part of the Blaze Project
tl;dr: We evaluate dask graphs with a variety of schedulers and introduce a new distributed memory scheduler.
Dask.distributed is new and is not battle-tested. Use at your own risk and adjust expectations accordingly.
Evaluate dask graphs
Most dask users use the dask collections, Array, Bag, and
DataFrame. These collections are convenient ways to produce
dask graphs. A dask graph is a dictionary of tasks. A task is a tuple with a
function and arguments.
The graph comprising a dask collection (like a dask.array) is available through
its .dask attribute.
>>> import dask.array as da
>>> x = da.arange(15, chunks=(5,)) # 0..14 in three chunks of size five
>>> x.dask # dask array holds the graph to create the full array
{('x', 0): (np.arange, 0, 5),
('x', 1): (np.arange, 5, 10),
('x', 2): (np.arange, 10, 15)}Further operations on x create more complex graphs
>>> z = (x + 100).sum()
>>> z.dask
{('x', 0): (np.arange, 0, 5),
('x', 1): (np.arange, 5, 10),
('x', 2): (np.arange, 10, 15),
('y', 0): (add, ('x', 0), 100),
('y', 1): (add, ('x', 1), 100),
('y', 2): (add, ('x', 2), 100),
('z', 0): (np.sum, ('y', 0)),
('z', 1): (np.sum, ('y', 1)),
('z', 2): (np.sum, ('y', 2)),
('z',): (sum, [('z', 0), ('z', 1), ('z', 2)])}Hand-made dask graphs
We can make dask graphs by hand without dask collections. This involves creating a dictionary of tuples of functions.
>>> def add(a, b):
... return a + b
>>> # x = 1
>>> # y = 2
>>> # z = add(x, y)
>>> dsk = {'x': 1,
... 'y': 2,
... 'z': (add, 'x', 'y')}We evaluate these graphs with one of the dask schedulers
>>> from dask.threaded import get
>>> get(dsk, 'z') # Evaluate graph with multiple threads
3
>>> from dask.multiprocessing import get
>>> get(dsk, 'z') # Evaluate graph with multiple processes
3We separate the evaluation of the graphs from their construction.
Distributed Scheduling
The separation of graphs from evaluation allows us to create new schedulers. In particular there exists a scheduler that operates on multiple machines in parallel, communicating over ZeroMQ.
This system has a single centralized scheduler, several workers, and potentially several clients.
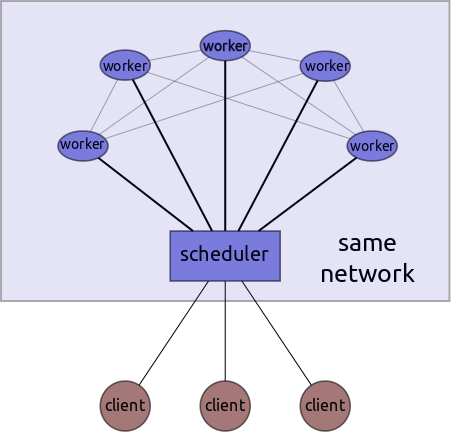
Clients send graphs to the central scheduler which farms out those tasks to workers and coordinates the execution of the graph. While the scheduler centralizes metadata, the workers themselves handle transfer of intermediate data in a peer-to-peer fashion. Once the graph completes the workers send data to the scheduler which passes it through to the appropriate user/client.
Example
And so now we can execute our dask graphs in parallel across multiple machines.
$ ipython # On your laptop $ ipython # Remote Process #1: Scheduler
>>> def add(a, b): >>> from dask.distributed import Scheduler
... return a + b >>> s = Scheduler(port_to_workers=4444,
... port_to_clients=5555,
>>> dsk = {'x': 1, ... hostname='notebook')
... 'y': 2,
... 'z': (add, 'x', 'y')} $ ipython # Remote Process #2: Worker
>>> from dask.distributed import Worker
>>> from dask.threaded import get >>> w = Worker('tcp://notebook:4444')
>>> get(dsk, 'z') # use threads
3 $ ipython # Remote Process #3: Worker
>>> from dask.distributed import Worker
>>> w = Worker('tcp://notebook:4444')
>>> from dask.distributed import Client
>>> c = Client('tcp://notebook:5555')
>>> c.get(dsk, 'z') # use distributed network
3Choose Your Scheduler
This graph is small. We didn’t need a distributed network of machines to compute it (a single thread would have been much faster) but this simple example can be easily extended to more important cases, including generic use with the dask collections (Array, Bag, DataFrame). You can control the scheduler with a keyword argument to any compute call.
>>> import dask.array as da
>>> x = da.random.normal(10, 0.1, size=(1000000000,), chunks=(1000000,))
>>> x.mean().compute(get=get) # use threads
>>> x.mean().compute(get=c.get) # use distributed networkAlternatively you can set the default scheduler in dask with dask.set_options
>>> import dask
>>> dask.set_options(get=c.get) # use distributed scheduler by defaultKnown Limitations
We intentionally made the simplest and dumbest distributed scheduler we could think of. Because dask separates graphs from schedulers we can iterate on this problem many times; building better schedulers after learning what is important. This current scheduler learns from our single-memory system but is the first dask scheduler that has to think about distributed memory. As a result it has the following known limitations:
- It does not consider data locality. While linear chains of tasks will execute on the same machine we don’t think much about executing multi-input tasks on nodes where only some of the data is local.
- In particular, this scheduler isn’t optimized for data-local file-systems like HDFS. It’s still happy to read data from HDFS, but this results in unnecessary network communication. We’ve found that it’s great when paired with S3.
- This scheduler is new and hasn’t yet had its tires kicked. Vocal beta users are most welcome.
- We haven’t thought much about deployment. E.g. somehow you need to ssh into a bunch of machines and start up workers, then tear them down when you’re done. Dask.distributed can bootstrap off of an IPython Parallel cluster, and we’ve integrated it into anaconda-cluster but deployment remains a tough problem.
The dask.distributed module is available in the last release but I suggest
using the development master branch. There will be another release in early
July.
Further Information
Blake Griffith has been playing with
dask.distributed and dask.bag together on data from
http://githubarchive.org. He plans to write a
blogpost to give a better demonstration of the use of dask.distributed on
real world problems. Look for that post in the next week or two.
You can read more about the internal design of dask.distributed at the
dask docs.
Thanks
Special thanks to Min Regan-Kelley, John Jacobsen, Ben Zaitlen, and Hugo Shi for their advice on building distributed systems.
Also thanks to Blake Griffith for serving as original user/developer and for smoothing over the user experience.
blog comments powered by Disqus