Building Computations Non-trivial results
In my last post I described a base type that represented a computation as a directed acyclic graph. In my post on preliminary results I showed how we could write Fortran code for a simple matrix expression. In this post I want to show how unificaiton, rewrite rules, and manipulations on computations can compile computations from fairly complex matrix expressions.
Inputs
Lets begin with a complex expression and a set of assumptions
expr = (Y.I*Z*Y + b*Z*Y + c*W*W).I*Z*W
assumptions = Q.symmetric(Y) & Q.positive_definite(Y) & Q.symmetric(X)We also specify a list of conditional rewrite patterns. A pattern has the following form
Source: alpha*A*B
Target: SYMM(alpha, A, B, S.Zero, B)
Wilds: alpha, A, B
Condition: Q.symmetric(A) | Q.symmetric(B)This means that we convert the expression alpha*A*B into the computation SYMM(alpha, A, B, S.Zero, B) (a SYmmetric Matrix Multiply) for any (alpha, A, B) when either A is symmetric or B is symmetric.
Thanks to unification rewrite patterns are easy to write. Someone who is familiar with BLAS/LAPACK but unfamiliar with compilers would be able to make these easily.
Expressions to Computations
Each pattern is turned into a function/rule that transforms an expression into a computation. We start with an identity computation
expr = (Y.I*Z*Y + b*Z*Y + c*W*W).I*Z*W
assumptions = Q.symmetric(Y) & Q.positive_definite(Y) & Q.symmetric(X)
identcomp = Identity(expr)
identcomp.show()Computations are able to print themselves in the DOT Language enabling simple visualization. Here we see a computation that produces the expression we want but its input is the same. We’d prefer one that had more atomic inputs like a, b, c, W, X, Y, Z
Our patterns know how to break down big expressions into smaller ones by adding the right computation (e.g alpha*A*B -> alpha, A, B via SYMM.) We convert each of our patterns into a rule. This rule looks at the inputs and, if it finds a matching expression adds on a new computation to break down that expression. We use branching strategies to orchestrate how all of these rules are applied. This is accomplished in the last line of the make_matrix_rule function
def make_matrix_rule(patterns, assumptions):
rules = [expr_to_comp_rule(src, target, wilds, cond, assumptions)
for src, target, wilds, cond in patterns]
return exhaust(multiplex(*map(input_crunch, rules)))This function combines logic (patterns/assumptions) with control (exhaust/multiplex/input_crunch) to create a complete algorithm. We apply this algorithm to our identity computation and pull off a compiled result
rule = make_matrix_rule(patterns, assumptions)
comp = next(rule(identcomp))
comp.show()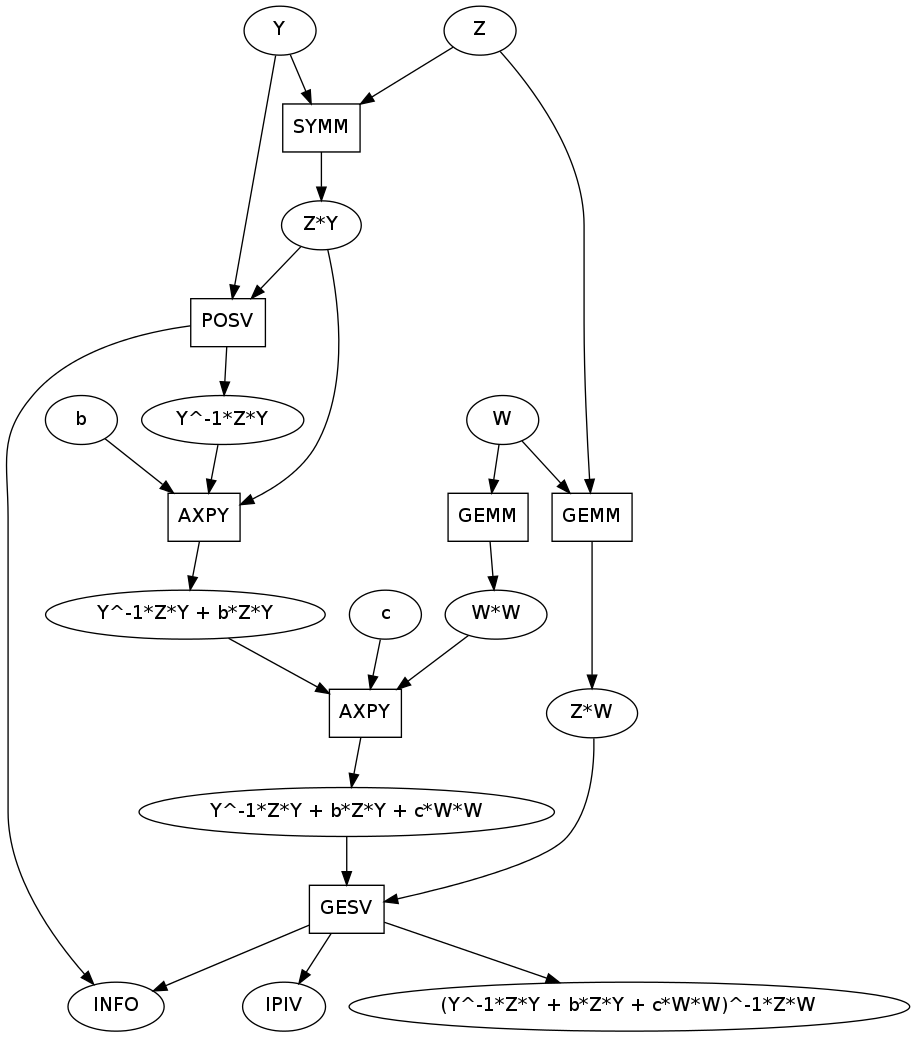
We still have same output but now the input is broken down into smaller pieces by a set of computations. These computations are arranged in a graph based on their dependencies. We had to use a GESV, a POSV, two GEMMs a SYMM and two AXPYs to break down this computation. Our inputs are now a,b,c,W,X,Y,Z as desired.
rule(identcomp) iterates over all possible computations to compute this expression. If you are not satisfied with the computation above you may ask for another.
Inplace Computations
The BLAS/LAPACK routines are inplace; they write their results to the memory locations of some of their inputs. The above matheamtical graph doesn’t have the necessary information to think about this computational concern. We have a separate system to compile and optimize inplace computations.
from sympy.computations.inplace import inplace_compile
icomp = inplace_compile(comp)
icomp.show()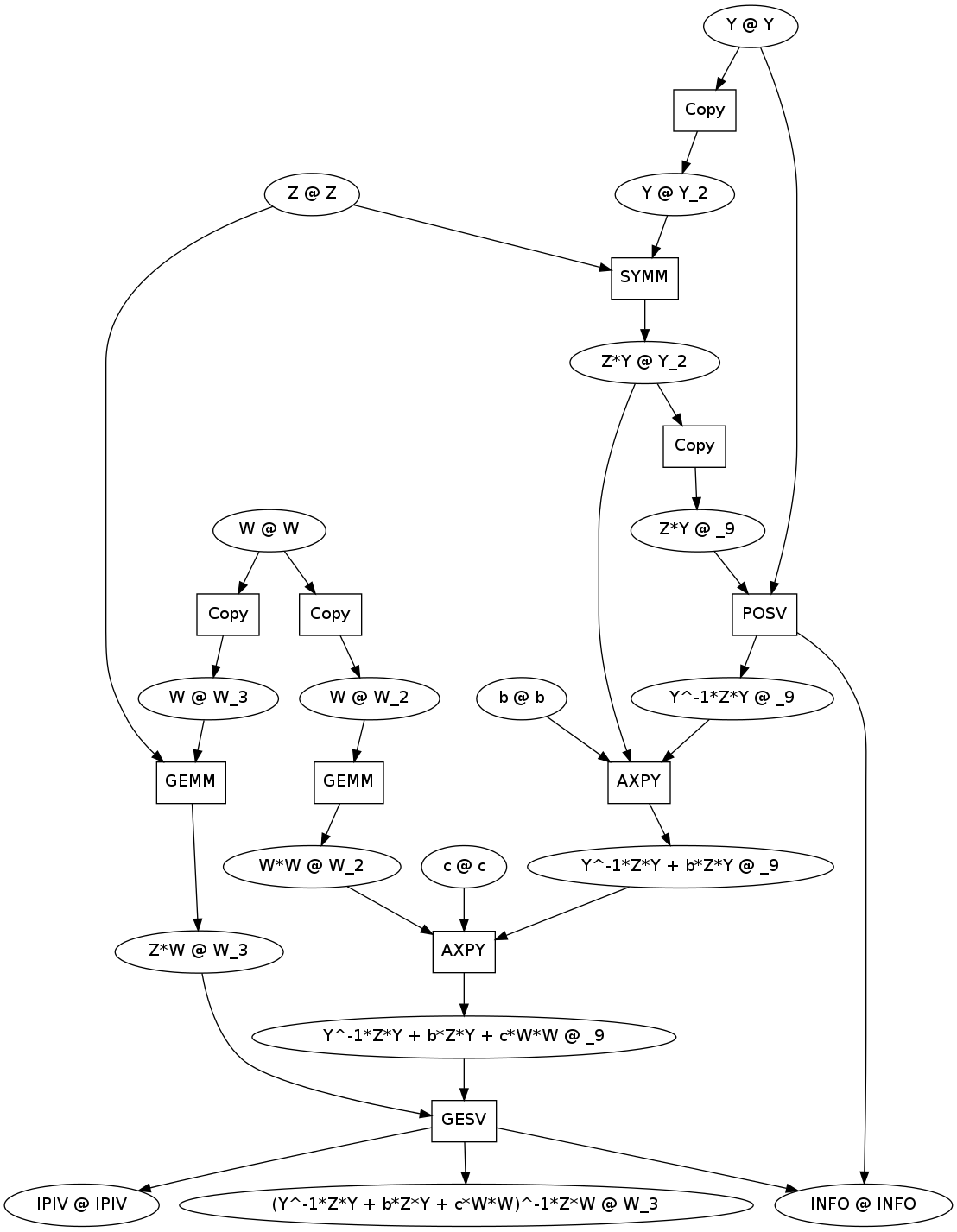
Each variable is now of the form
Mathematical Expression @ memory location
We have introduced Copy operations into the graph where necessary to prevent dangerous overwrites.
If you track the memory locations you can see which BLAS/LAPACK operations overwrite which variables. For example Z is never overwritten and so is never copied. On the other hand W is used in two overwrite operations and so it is copied to two new variables, W_2 and W_3. Copies are not added if obviously unnecessary.
Future Work
There are a couple of small items and one large one.
-
An expert in BLAS/LAPACK will note that there are some issues with my graphs; they are not yet ideal. I don’t handle
IPIVpermutation operations well (I need to add some new patterns), I am overwrie theINFOout parameter, and there are a few cases where a copy could be avoided by operation reordering. -
I need to refactor my old Fortran generation code to work with the new inplace system.
-
The largest challenge is to build strategies for intelligent application of rewrite rules. Expressions are now large enough and the list of patterns is now long enough so that checking all possiblities is definitely infeasible. I need to think hard about traversals. Fortunately this problem is purely algorithmic and has no connection to BLAS, inplace computations, etc…. I should be able to think about it in isolation.
Closing Note
Except for the mathematical definition of BLAS none of this code is specific to generating matrix computations. The majority of this technology isn’t even specific to building computations. The computaitonal core of most of the technologies isn’t even dependent on SymPy. My final sympy.computations.matrices directory is small.
Throughout this project I’ve tried to keep all of the technology as general as possible in hopes that others will make use of it. Only a small fraction of my work has been specific to my application. I hope that others find this work interesting. I hope that this technology enables a variety of other unrelated projects.
Links
blog comments powered by Disqus